하둡은 빅데이터를 분산해서 병렬 처리하는 프레임워크다.
데이터가 매우 큰 경우 하나의 시스템에서 처리할 수 없다. 그래서 시스템을 많이 두고 작업량을 분산시켜서 동시에 병렬 처리하는 방식을 택한다.
이 경우 다수의 시스템을 관리하는 역할을 수행해야 하는데, 이 역할 마스터 시스템이 수행하게 되고, 이를 마스터-슬레이브 구조라고 한다.
맵리듀스 프레임워크
하둡의 가장 기본이 되는 시스템이다. 맵(Map) + 리듀스(Reduce)의 합성어다.
하둡 이해에 꼭 필요한 개념이 맵리듀스와 HDFS이다.
HDFS(하둡분산파일시스템)은 데이터를 저장하는 쪽이고, 그 위에서 작업을 처리하는 쪽이 맵리듀스이다.
맵리듀스 프레임워크는 세 단계로 나누어진다.
맵(map): 분산된 데이터를 키(key)와 값(value)의 리스트로 모으는 단계다.
셔플(shuffle and sort): 맵 단계에서 나온 중간 결과를 해당 리듀스 함수에 전달하는 단계
리듀스(reduce): 리스트에서 원하는 데이터를 찾아서 집계하는 단계
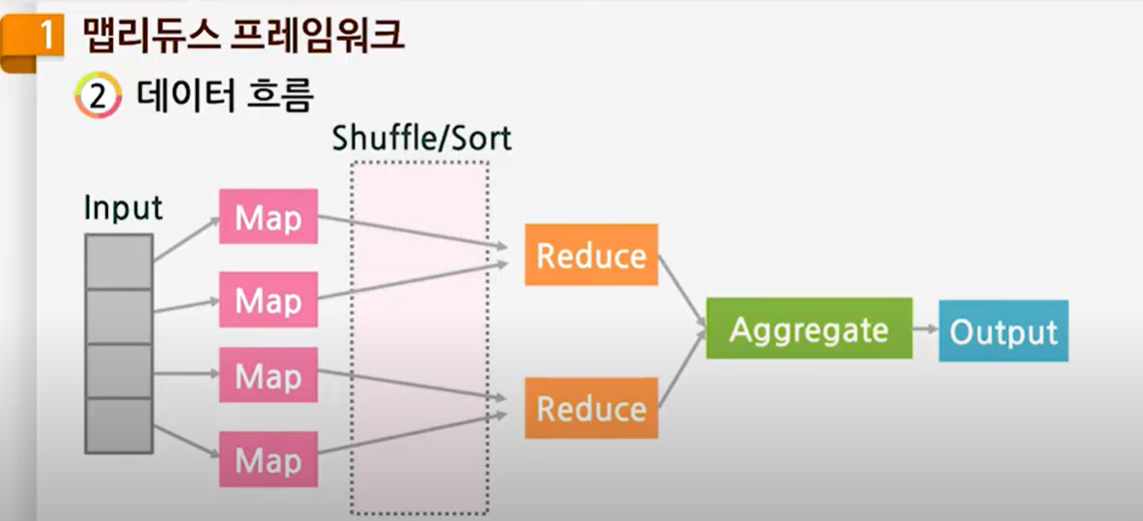
예를 들어 설문지 1만장(Input)을 한 명이 처리하기에는 오래 걸리므로 10명이 나눈다면(10개의 Map으로 분산) 데이터를 처리하는 시간이 단축될 것이다. 10명의 staff들은 설문지의 내용을 체크한다. 1번에 4번으로 체크했다면 Key는 1, Value는 4가 된다. 데이터를 처리하는 알고리즘, 로직이 각각의 Map에 담겨있다.
즉 데이터를 던져주고, Map 로직을 시스템에 던져줘야 시스템이 돌아간다. 각각의 Map 작업 노드는 로직을 보고 데이터 조사에 들어간다. 보통 단순한 로직이 입력되기 때문에 리소스를 많이 차지하지는 않는다.
여기에서 노드(node)란 개인용컴퓨터, 휴대전화, 프린터 등의 정보처리 장치를 의미하는데 쉽게 얘기해서 각각의 노드는 개별 노트북 한대라고 생각하면 된다.
Map 작업노드에서 나온 결과물을 Reduce작업 노드로 보내는 것을 Shuffle/Sort라고 한다. 딜러가 카드를 섞어서 나눠주는 것처럼 Map에서 나온 결과물(데이터)을 나눠주는 단계다. 이 작업을 하둡 엔진이 수행하게 된다.
shuffle/sort의 결과물이 Reduce노드로 전달되면 해당 데이터를 집계하고 최종 결과물을 내보낸다.
맵리듀스 분산 병렬 처리 방식
여기에서 개발자가 해야 하는 역할은 두가지다. 맵 함수를 정의하고 리듀스 함수를 정의하는 것이다.
맵 함수와 리듀스 함수가 어떤 input을 어떻게 받아서 로직을 처리하고 결과물을 어떤 형태로 냈으면 좋겠다 라는 것을 정의하는 것이다.
앞에서 맵 함수에서 나온 결과를 리듀스 함수로 보내는 셔플 단계를 하둡 시스템에서 수행한다고 했다. 마스터 노드(작업 관리자)와 슬레이브 노드(작업자)가 있는데, 마스터 노드는 시스템 리소스를 관리하면서 어떤 슬레이브 노드가 놀고 있는지를 체크한 후 어떤 슬레이브 노드에게 작업을 던져줘야 할지를 결정한다.
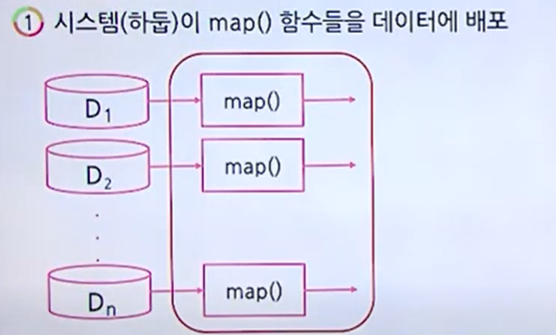
큰 데이터를 n개로 나누고, 각각의 Map노드에 전달한다.

Map 함수의 처리 로직에 따라 분산된 데이터를 key와 value 쌍으로 추출한다.
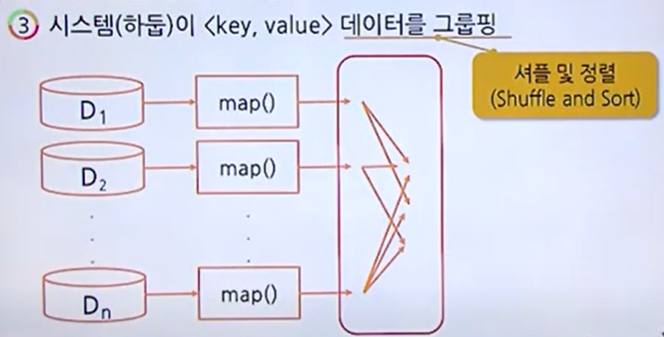
하둡이 리듀스에게 셔플링해서 전달한다.
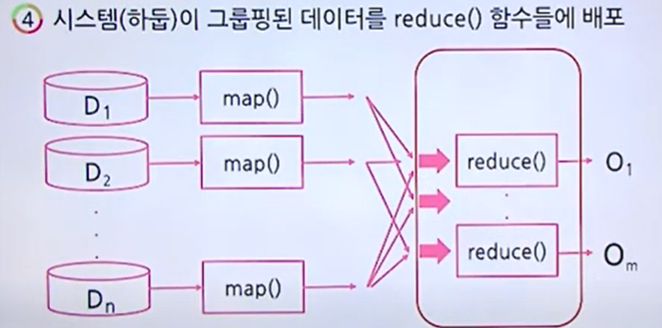
리듀스 노드에 있는 리듀스 함수에 따라 입력을 받게 되고, 내부 로직에 따라 결과물이 출력된다.

리듀스 함수는 Map 함수에서 출력된 key, value 쌍을 입력 받아서 로직 처리 후 결과를 낸다.
맵리듀스 분산 병렬 처리 예시

해당 개념을 설명하기 가장 좋은 예시가 Word Count이다.
Input으로 들어오는 데이터에는 총 9개의 단어가 있다. 이를 각각 3개로 나누어 3개의 작업 노드로 전달한다.
Splitting 된 각각의 데이터 조각들 안에는 구분자(공백)로 구분된 단어가 있다. 이 데이터를 Map노드에서 입력된 로직에 따라 처리하게 된다. 1번 Map 노드에서는 (key = Deer, Value = 1), (key = Bear, Value = 1), (key = River, Value = 1) 형태로 처리하게 된다.
하둡 엔진은 Map에서 나온 결과를 섞고 정렬한다. 각각 셔플링을 하는 기준이 있는데, 해당 예제에서는 알파벳 순으로 정렬하였다.
리듀스 함수에서는 데이터를 집계한 후, Final 결과물을 내보낸다.
핵심 포인트
맵 노드에서는 나누어진 데이터를 입력받아 Key와 Value 쌍으로 처리한다.
맵리듀스 분산 병렬 처리에서는 맵, 셔플, 리듀스 단계를 거친다.
개발자는 맵 함수와 리듀스 함수의 로직을 정의해야 한다.
'빅데이터' 카테고리의 다른 글
| 하둡 데이터 처리 방식 구성 요소 (0) | 2021.05.10 |
|---|