하둡 개요
오픈소스 SW
HDFS + MapReduce
빅데이터 처리 프레임워크
다양한 하둡 에코 시스템으로 구성
결함 허용, 결함이 나도 작업이 중지되지 않고 계속 작업할 수 있는 환경
데이터 블록의 복사본을 중복 저장하고 유지
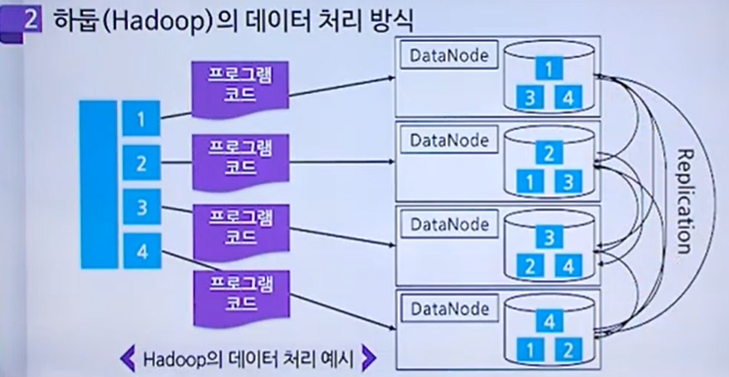
하둡의 데이터 처리 방식
데이터 블록 전송 단계
하나의 파일을 여러 블록으로 나누어 클러스터에 있는 데이터 노드들에게 분산 저장
데이터 블록 복제 단계
하나의 블록은 여러개의 복제본을 생성하여 분산 저장

원본 데이터를 4개의 블록으로 분할,
분할된 데이터를 복제하여
서로 다른 위치에 있는 각각의 데이터 노드에 분산 저장함
프로그램 코드 전송 단계
전송받은 데이터를 어떤 방식으로 처리할 것인지에 대한 로직이 담긴 프로그램이 있고, 이 코드를 전송하게 됨
데이터 병렬 처리 단계
맵리듀스 처리방식을 통해 데이터를 병렬처리 하도록 함
하둡의 구성 요소
하둡 공통(Hadoop Common)
하둡 분산 파일 시스템(HDFS)
하둡 YARN
하둡 맵리듀스(MapReduce)

버전 1.0에서는 데이터 처리를 위한 MapReduce와 데이터 저장을 위한 HDFS밖에 없었음.
2.0 버전으로 가면서 MapReduce 처리방식 이외에 실시간 처리방식, 대화형 처리방식, 이벤트 처리방식 등등 다양한 처리방식이 생겨났음. 다양한 데이터 처리방식이 생겨나면서 HDFS라는 공유자원을 원활하게 관리할 수 있도록 하는 관리 소프트웨어가 필요해졌음. 이를 YARN이라고 함.
1.0과 2.0 버전의 가장 큰 차이점은 YARN의 등장임.
하둡 공통
타 모듈들에 공통으로 필요한 라이브러리 및 유틸리티가 포함됨
Java Archive(JAR) 파일로 이루어짐
하둡을 기동하거나 셧다운 할 때 필요한 스크립트가 포함됨
하둡은 Java에 기반하여 만들어졌으므로 JRE1.6(Java Runtime Environment) 이상 요구
하둡 기동 및 셧다운 스크립트들은 보안이 중요하기 때문에 Secure Shell(SSH)를 요구함.
핵심 정리
- 하둡 1.0과 2.0 버전의 가장 큰 차이점은 자원관리소프트웨어 YARN의 등장임.
- 하둡 데이터 처리시 원본 데이터가 분할, 복제되어 각각의 데이터 노드들에 중복 저장됨.
'빅데이터' 카테고리의 다른 글
| 빅데이터 분산처리 맵리듀스 프레임워크 (0) | 2021.05.09 |
|---|